

If you’re in venture capital, recruiting, market intelligence, or SaaS growth—chances are you’ve searched for a clean, scalable way to extract data from Y Combinator’s startup directory.
Y Combinator (YC) has launched some of the world’s most valuable startups—Stripe, Airbnb, Coinbase, OpenAI—and every batch introduces 100+ fresh companies worth watching. But YC’s website doesn’t offer a public API, and manually copying data is time-consuming and error-prone.
In this guide, I’ll show you the easiest and fastest way to scrape YC startup data in 2025. No code. No scraping bans. No headaches.
Why Scrape Y Combinator?
Let’s start with the “why.” Here are real use cases:
- VCs & angel investors: Track emerging companies by batch, team size, or region.
- Recruiters: Discover startups hiring engineers, designers, PMs, and more.
- Founders: Benchmark competitors or find partners in your space.
- Growth marketers: Build high-quality outreach lists for B2B products.
- Journalists & analysts: Monitor trends across YC’s portfolio.
YC’s site shows a lot of data—but not in exportable form. There’s no easy way to sort, filter, or analyze it unless you scrape it.
What Kind of YC Data Can You Extract?
With the right tool, you can extract:
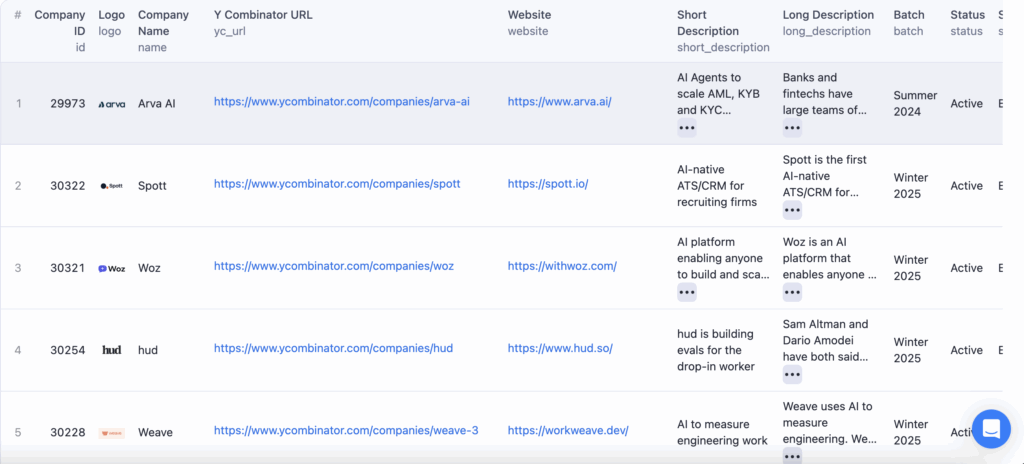
- ✅ Company name, website, logo
- ✅ Short & long descriptions
- ✅ YC batch (e.g. Summer 2024)
- ✅ Tags (industry, region, status)
- ✅ Founders’ names, bios, LinkedIn, Twitter
- ✅ Job postings (title, location, salary)
- ✅ Team size, location, year founded
- ✅ Social links (LinkedIn, Crunchbase, X, Facebook)
All in structured JSON or CSV, ready for Airtable, Notion, or your CRM.
The Problem With DIY Scraping
If you’ve tried scraping Y Combinator manually or with Python libraries like BeautifulSoup or Scrapy, you’ve probably hit these issues:
- 🔒 YC data loads dynamically via Algolia (requires reverse engineering search requests)
- 🔄 Data is paginated with JS—hard to crawl reliably
- 🧠 Founders & jobs live on separate subpages
- ⚠️ You risk IP blocks if you don’t rotate proxies
Building and maintaining a scraper for this is non-trivial, especially if you want to keep it up to date.
The Fastest Way: Use the Y Combinator Scraper on Apify
This scraper was built specifically for YC’s site. It handles:
- ✅ Advanced filtering and search
- ✅ Proxy rotation to avoid bans
- ✅ Extraction of all public fields (including founders & job postings)
- ✅ Output in JSON, CSV, or Excel formats
You can use it with zero setup. Just paste in a filtered YC URL and hit run.
🔍 Example input URL:
https://www.ycombinator.com/companies?batch=Summer%202025&industry=B2B&isHiring=true
How to Use It (Step-by-Step)
- 👉 Go to this Apify actor
- Click Try for free
- Paste in your YC company search URL (with filters if needed)
- Optionally add a keyword search or change the sort order
- Click Run and let it work
- Download your results in JSON, CSV, or Excel
You can even schedule it to run weekly to track new startups over time.
Use Cases That Work Right Now
- 🔎 Find all YC startups hiring in Europe with a team size under 50
- 📈 Monitor all B2B companies in Winter 2025 batch
- 🧑💼 Build a founder outreach list with LinkedIn profiles
- 🛍️ Enrich Shopify/Stripe product lists with YC competitors
- ✍️ Create automated reports for investors or newsletters
Final Thoughts
Scraping Y Combinator data doesn’t have to be technical, fragile, or slow.
With the Y Combinator Scraper on Apify, you can get rich, structured data on the world’s most exciting startups—in minutes.
No coding. No proxies. No limits.
This tool powers my own startup research at Scraptorium—and it just works.
If you’re serious about finding the next Stripe before everyone else, start scraping smarter.
Try it now → Y Combinator Scraper on Apify
Got feedback or a cool use case? Let me know—I’d love to hear how you’re using it.